


3. Sockets
Sockets realisieren eine Schnittstelle zur Interprozesskommunikation, durch welche Prozesse des gleichen oder auch unterschiedlicher Rechner miteinander kommunizieren können. Durch das Nutzen von Sockets wird das Finden des Kommunikationspartners, sowie die generell unterliegende Netzwerktopologie und Rechnerarchitektur komplett abstrahiert. Ein Socket wird im UNIX-Betriebssystem ähnlich wie eine Datei oder ein Prozess eindeutig durch einen File-Deskriptor identifiziert. File-Deskriptoren (kurz: FD) wiederum sind einfache Integer-Zahlen, die offenen Dateien zugeordnet sind. Abb. 1-1 verdeutlicht die Funktion der File-Deskriptoren. Es lässt sich deutlich erkennen, dass jeder File-Deskriptor vom Typ Integer über eine Tabelle einer Datei zugeordnet ist. Nicht nur Dateien sind File-Deskriptoren zugeordnet, sondern auch Geräte und Prozesse. Der Deskriptor ist dabei nur solange gültig, solange das referenzierte Objekt (Datei, Gerät oder Prozess) existiert.
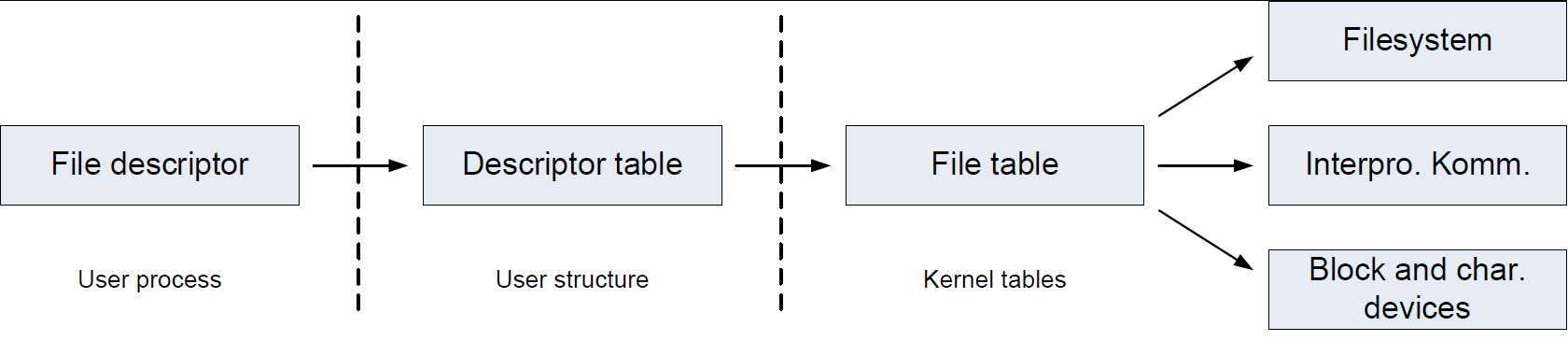
Da unter Unix alle Ein- und Ausgabeeinheiten Geräte sind, denen deshalb ein FD zugeordnet ist, können Prozesse mittels der Socket-Schnittstelle auch über ein Netzwerk hinweg auf Eingabe- und Ausgabeeinheiten zugreifen.
3.1 Internet - Sockets
Folgend konzentrieren wir uns auf Sockets zur Kommunikation über das Internet: Es gibt zwei für diese Veranstaltung relevanten Varianten:
- „Stream-Sockets“ und
- „Datagram-Sockets“
Sie unterscheiden sich bezüglich des Dienstes (zuverlässig oder nicht zuverlässig), den sie anbieten.
Im ersten Fall wird eine fehlerfreie Übertragung sichergestellt, d. h. die Reihenfolge der gesendeten Daten wird eingehalten, auch im Fall von Datenverlusten. Die Socketschnittstelle lässt jedoch offen, wie bei einem Stream-Socket Verluste kompensiert werden bzw. die korrekte Reihenfolge der Daten gewährleistet wird. Eine einfache Möglichkeit ist beispielsweise, verlorengegangene Daten erneut zu übertragen. Es könnten jedoch auch Fehlerkorrekturverfahren Anwendung finden. Im zweiten Fall hingegen, dem Datagram-Socket, können Daten verloren gehen.
Werden Daten beim Empfänger korrekt empfangen, dann gehen wir davon aus, dass die Inhalte fehlerfrei sind. Dies bedeutet, dass Daten nicht innerhalb eines Rechners verfälscht werden.
Eine weitere Variante, die Sie kennen sollten, die aber nicht in dieser Veranstaltung benötigt wird, ist der „Raw-Socket“. Mit diesem Typ können Sie neue Internet-Protokolle erstellen und den Zugriff auf diese Protokolle mittels der Socket-Schnittstelle ermöglichen.
3.2 Initiierung eines Sockets
Stellen Sie sich nun vor, sie möchten, dass ein Prozess X im Rechner A und ein Prozess Y im Rechner B miteinander kommunizieren. Die beiden Prozesse befinden sich in der Regel in unterschiedlichen Rechnern. Allerdings können sie sich auch in einem Rechner befinden.
3.2.1 Protokollfamilie
Dies reicht jedoch noch nicht aus. Zusätzlich wird die Angabe benötigt zu welchem Prozess in welchem Rechner eine Kommunikation hergestellt werden soll. Also muss zusätzlich angegeben werden, dass mit diesem gerade erzeugten Socket eine Kommunikation mit Prozess Y im Rechner B hergestellt werden soll. Um einen Socket mit diesen beiden Größen zu assoziieren, werden entsprechende Funktionen bereitgestellt, auf die folgend näher eingegangen wird.
Zu diesem Zeitpunkt wurde noch nicht festgelegt, wie ein Rechner und ein Prozess adressiert werden bzw. wie diese Adressen ermittelt werden. Konzentrieren wir uns zunächst auf die Rechneradresse.
Eine Rechneradresse kann eine Telefonnummer im ISDN oder Mobilfunknetz oder beispielsweise eine Internetadresse sein. Alle diese Adressen besitzen einen unterschiedlichen Aufbau. Die Socket-Schnittstelle muss in der Lage sein, sie zu interpretieren. Wie kann so etwas realisiert werden?
Die Adresse selbst wird in der Regel in Textform angegeben und ebenfalls als Parameter übergeben. Hierdurch wird vermieden, dass eine Telefonnummer als Internetadresse interpretiert wird oder umgekehrt.
3.2.2 Portnummern
Nachdem nun geklärt ist, wie ein Rechner adressiert wird, bleibt die Frage offen, wie ein Prozess adressiert wird?
Man könnte sich vorstellen, dass zur Prozessadressierung die Prozessnummer verwendet wird, die jeder Prozess bei seinem Start erhält. Dies ist allerdings sehr ungünstig, da Prozessnummern in der Regel dynamisch vergeben werden. Beispielsweise hat ein Prozess, der Dateien über das Netzwerk sendet, mal die Prozessnummer 4711 und ein andermal die Prozessnummer 1147.
Ein Prozess, der mit einem Prozess in einem entfernten Rechner kommunizieren möchte, benötigt in diesem Fall eine Liste aller möglichen Prozesse. Dies ist sehr umständlich. Aus diesem Grund führt die Socket-Schnittstelle den Begriff des Ports ein. Ein Port kann als Synonym für einen Dienst verstanden werden. Jedem Dienst wird ein Port zugeordnet. Beispielsweise ist dem WEB-Dienst die Port-Nummer 80 zugeordnet. Wenn also ein Prozess mit einem anderen Prozess kommunizieren möchte, der einen WEB-Dienst anbietet, wird dem Socket-Aufruf die Port-Nummer 80 als Parameter übergeben. Im Zielrechner sorgt ein Hintergrundprozess dafür, dass die Zuordnung von der Port-Nummer zur Prozessnummer durchgeführt wird. Eine Übersicht der Port-Nummer ist in jedem Unix-System der Datei /etc/services zu entnehmen. Zusätzlich gibt die folgende Tabelle eine Auswahl an besonders häufig verwendeten Ports.

3.2.3 Stream- vs. Datagram-Sockets
Bei einer zuverlässigen Übertragung mittels Stream-Sockets werden andere Voraussetzungen für den Client und Server gelten als bei einer unzuverlässigen Übertragung mittels Datagram-Sockets. Beispielsweise müssen bei der zuverlässigen Übertragung immer die beiden kommunizierenden Prozesse miteinander verbunden werden. Hierzu verwendet der Client den connect()-Befehl. Der Server quittiert den Verbindungswunsch mit einem accept()-Befehl.
3.2.4 Client vs. Server
Des Weiteren können sich die Anforderungen vom Client und Server unterscheiden. Server können in der Regel mehr als nur einen Prozess bedienen. Z. B. kann ein Web-Server in der Regel mit einer Vielzahl von Client-Prozessen kommunizieren. Zu diesem Zweck bietet die Socket-Schnittstelle die listen()-Funktion an. Immer, wenn ein Client eine neue Kommunikation initiieren möchte, wird durch die listen()-Funktion ein neuer Socket initiiert. Später folgende Daten werden direkt an diesen neuen Socket geleitet.
3.3 Datenübertragung
Nachdem ein Socket initiiert — man sagt auch „geöffnet“ — wurde, können Daten über den Socket versendet bzw. empfangen werden. Hierzu werden die Funktionen send() und recv() verwendet.
3.4 Beenden der Kommunikation
Wenn alle Daten übertragen wurden, wird der Socket mit der Funktion close() beendet. Im Falle eines Fehlers wird die reset()-Funktion verwendet.
3.5 Socket-Adress-Struktur
Da die Socket-Schnittstelle für verschiedene Netzwerk-Protokolle (Internet, XNS, …) konzipiert wurde, sind alle Funktionen, die Netzwerkadressen auswerten, so allgemein gehalten, dass sie zuerst die Protokoll-Familie auswerten und zusätzlich noch die Größe der Adress-Struktur als Parameter erwarten.
Die allgemeine Adress-Struktur (siehe Listing 1) der Socket-Schnittstelle besteht daher auch nur aus einer (16-Bit, unsigned short int) Kennung der Protokoll-Familie sa_family, und einer festgelegten Anzahl von Adress-Bytes sa_data (hier 14 Bytes), die protokoll- spezifisch die Adresse repräsentieren.
struct sockaddr {
u_short sa_family;
char sa_data[14];
}
Im Folgenden muss beachtet werden, dass im Gegensatz zu einer Telefonnummer (-adresse), die aus 14 Zeichen (14 Bytes) besteht, eine Internet-Adresse (IP-Adresse) – des Internets der Version 4 – aus 32 Bit besteht. Die 32 Bit werden zur besseren Lesbarkeit in Gruppen von 4 Byte geteilt. Jedes Byte wird dezimal dargestellt und die einzelnen Bytes durch einen Punkt voneinander getrennt. So hat beispielsweise ein Rechner im Netz der TU-Berlin die Internet-Adresse 130.149.49.1. Deshalb werden die 14 Bytes der Komponente char sa_data aus der Struktur sockaddr weiter aufgeteilt, was letztendlich zu der Struktur sockaddr_in (siehe Listing 2) führt:
struct sockaddr_in {
short int sin_family;
unsigned short int sin_port;
struct in_addr sin_addr;
unsigned char sin_pad[8];
};
Wie man erkennen kann, besteht eine Socket-Adresse für das Internet aus dem sin_port, der eigentlichen Internetadresse sin_addr und aus Füllbytes (sin_pad). Die sockaddr_in-Struktur bestand in früheren Implementationen aus verschiedenen Elementen, die eine IP-Adresse auf unterschiedliche Weise (Byte-Reihenfolge) darstellten.
struct in_addr {
unsigned long;
int s_addr;
};
Heute besteht diese Struktur (siehe Listing 3) nur noch aus einem Element s_addr, sodass eigentlich die Struktur unnötig ist, aber aus Kompatibilitätsgründen weiter verwendet wird (was sich auch in naher Zukunft nicht ändern wird). So kann man auf die als long int dargestellte IP-Adresse nur über den Ausdruck sin_addr.s_addr zugreifen.
3.6 Byte-Order
Da ein Netzwerk (normalerweise) heterogene Rechner, also Rechner unterschiedlicher Architekturen und mit unterschiedlicher Datenrepräsentation (Byte-Folge innerhalb eines Datenwortes) miteinander verbinden kann bzw. soll, muss eine einheitliche Datenrepräsentation der zu übertragenen Daten definiert werden. Im OSI-Referenzmodell übernimmt die Schicht 6 (Präsentations-Schicht) unter anderem diese Datenrepräsentation der Anwendungsdaten.
Während das Phänomen, dass bei einigen Computersystemen Bytes nicht aus 8 Bits sondern aus 9, 11 oder 12 Bits bestehen, langsam verschwindet und daher vernachlässigt werden kann, bleibt ein anderes Problem weiterhin bestehen: Verschiedene Computersysteme speichern bei Datenworten, die aus mehreren Bytes bestehen, die einzelnen Bytes in unterschiedlicher Reihenfolge. So kann ein 16-Bit Datenwort (short int) auf zwei verschiedene Arten gespeichert werden, entweder mit dem niederwertigen Byte an der Startadresse („Little-Endian“-Anordnung) oder mit dem höherwertigen Byte an der Startadresse („Big-Endian“-Anordnung).
Die Anordnung eines 32-Bit-Datenwortes entspricht dabei – durch Aufteilung in zwei 16-Bit-Worte – der Anordnung zweier Bytes in einem 16-Bit-Wort. So verwenden Intel (80x86), DEC VAX, … die „Little-Endian“-Anordnung, wogegen Motorola (68xxx), Sun Sparc und IBM-Großrechner (IBM 370, …) die „Big-Endian“-Anordnung verwenden.
Beim Internet-Protokoll wird die „Big-Endian“-Anordnung verwendet. Dem Programmierer von Applikationen werden eine Reihe von Funktionen angeboten, die 16-Bit-Worte bzw. 32-Bit-Worte von der Netz-Repräsentation in die Repräsentation des lokalen Rechners (und umgekehrt) umformen.
Unabhängig davon, ob der lokale Rechner eventuell die „Big-Endian“-Anordnung schon verwendet, sollte man diese Funktionen immer benutzen, da eine Portierung des entwickelten Programms auf andere Rechner sonst (fast) unmöglich ist.
Auf Rechnern, die schon die „Big-Endian“-Anordnung verwenden, sind diese Funktionen Leer-Funktionen, d. h. sie liefern als Ergebnis die Daten unverändert zurück. Die IP-Port-Nummer und IP-Adresse müssen in der sockaddr_in-Struktur in Netz-Repräsentation gespeichert werden. Wichtige Funktionen zur Umwandlung der Adress-Darstellung sind in Listing 4 dargestellt.
/* htons() bzw. htonl() ntohs() bzw. ntohl() */ /* Beispiele: */ in_addr.sin_port = htons(13); printf(“Port-Nr.: \%d\n”, ntohs(in_addr.sin_port) );
3.7 I/O-Multiplexing unter Unix
Wie in den vorhergehenden Abschnitten deutlich geworden ist, müssen verschiedene Verbindungen gleichzeitig aufgebaut und I/O-Events verarbeitet werden. Hinzu kommen die Standard-Filedeskriptoren für die Ein- und Ausgabe zum Lesen bzw. Ausgeben von Textdaten.
Um nun nicht dauerhaft einzelne Deskriptoren abfragen (= pollen) zu müssen, bietet Unix den Systemaufruf select() an. Dieser erhält eine Liste aller relevanten Deskriptoren und legt den Prozess schlafen, solange kein Ereignis eingetreten ist (blockierender Systemaufruf).
Tritt ein Ereignis auf, z. B. der Empfang eines Datenpaketes, so weckt der Scheduler des Linux-Kernels den Prozess wieder auf und teilt ihm mit, auf welchem Deskriptor (oder auf welchen Deskriptoren) ein Ereignis stattgefunden hat.
3.8 Stream-Sockets
Wird beim Internet eine Kommunikation mit einem Stream-Socket initiiert, dann werden die zu sendenden Daten mittels des Transmission Control Protocol (TCP) übertragen. Ohne näher auf den Aufbau des Protokolls einzugehen, handelt es sich beim TCP um ein verbindungsorientiertes und zuverlässiges Protokoll. Bevor Daten übertragen werden können, muss zwischen Sender und Empfänger eine Verbindung aufgebaut werden. Die Verbindung wird durch einen 3-Wege-Handshake initiiert. Wenn die Verbindung nicht mehr benötigt wird, dann wird sie abgebaut. Während der Datenübertragungsphase erwartet das Protokoll von den Applikationen, dass die zu übertragenen Daten in Form von Datenblöcken übergeben werden. Die Datenblöcke werden segmentiert und in Paketen verpackt über das Netzwerk übertragen.
Im Netzwerk kann es passieren, dass Pakete nicht, mehrfach oder in vertauschter Reihenfolge beim Empfänger ankommen. TCP ist in der Lage solche Fehler zu korrigieren, ohne dass die Applikation sich darum kümmern muss. Da die Korrektur der Fehler Zeit benötigt, übernimmt TCP keine Garantie zu welchem Zeitpunkt Daten beim Empfänger eintreffen. Die Daten werden also nach dem Best-Effort-Prinzip übertragen.
TCP wird für Bulk-Transfer-Anwendungen verwendet, bei der große Datenmengen übertragen werden müssen (z. B. das File Transfer Protokoll (FTP)) oder nicht-interaktive Multimediaapplikationen (z. B. Video- oder Audio-Streaming (z. B. YouTube)). Dabei darf nicht verwechselt werden, dass im Gegensatz zu den nicht-interaktiven Multimediaapplikationen, interaktive Multimediaapplikationen (z. B. Skype) den Datagram-Socket verwenden und keinen Stream-Socket.
Aber auch Applikationen, die vergleichsweise geringe Datenmengen produzieren, verwenden TCP. Z. B. das Hypertext Transfer Protocol (HTTP) zur Kommunikation mit Web-Servern oder Terminal-Emulationen basieren auf TCP.