Dieser Themenblock des Praktikums Kommunikationsnetze beschäftigt sich mit ARQ-Protokollen.
Im vorherigen Block des Praktikums Kommunikationsnetze wurden Eigenschaften und Parameter der physikalischen Schicht untersucht. Es wurden wichtige Eigenschaften des physikalischen Kanals auf der Bit-Ebene und der Ebene eines Rahmens (Frames) analysiert. Es wurde auch der Einfluss von Leitungscodes (“Non Return to Zero” (NRZ) und Manchester Codierung) und eines Scramblers auf die BER gezeigt. Mit den Kenntnissen der Eigenschaften des physikalischen Kanals wurden anschließend die Grundvoraussetzungen geschaffen, ein Protokoll zu konstruieren: Einzelne Bits wurden zu Rahmen zusammengefasst. Ein Rahmen besitzt die Eigenschaft, durch eine Prüfsumme Bitfehler zu erkennen (“Error Detection”). Eine wichtige Eigenschaft des Empfängers - sich auf den empfangenen Datenstrom zu synchronisieren - beeinflusst die Verlustrate von Rahmen.
In diesem Block sollen Protokolle entwickelt werden, die eine fehlerfreie Übertragung von Rahmen zwischen einem Sender und einem Empfänger gewährleisten. Hierzu wird ein Einblick in den Prozess zum Erstellen von Protokoll-Software gegeben. Dazu wird der Umgang mit der häufig benutzten Entwicklungsumgebung SDT vorgestellt und Erfahrungen mit dem Einsatz einer formalen Beschreibungssprache (SDL) für die Spezifikation von Kommunikationsprotokollen vertieft. Der komplette Entwicklungsprozess für eine Protokollsoftware lässt sich grob in folgende Phasen einteilen:
- Spezifikation und Entwurf,
- Simulation,
- Validierung (Überprüfung),
- Implementierung in eine Laufzeitumgebung (Plattform) und
- Leistungsanalyse des Protokolls.
SDT unterstützt fast alle Phasen der Protokollentwicklung mit passenden Werkzeugen. Die einzige Ausnahme ist die Leistungsanalyse des Protokolls. Sie wird effektiv nur durch Simulationstools oder in einer realen Laufzeitumgebung durchgeführt. Die Phasen lassen sich oft zeitlich nicht genau voneinander abgrenzen, da man beim Aufdecken von Fehlern und Abweichungen von der Vorgabe zu früheren Arbeitsschritten zurückkehren muss.
Zunächst wird im Rahmen dieses Blocks die Protokolltechnik “Send-and-Wait” behandelt. Anschließend wird das “Go- Back-N”-Protokoll näher untersucht. Diese Protokolle gehören zur Gruppe der ARQ-Protokolle. ARQ-Protokolle besitzen eine Fehlererkennung (Error Detection) und -behebung (Error Control), d.h. sie fordern bei erkannten Fehlern automatisch die Wiederholung der letzten Übertragung an. In der Art und Weise wie sie das tun, unterscheiden sich diese Protokolle, was zum Teil erhebliche Auswirkungen auf die “Restfehlerwahrscheinlichkeit” hat. Benutzt werden ARQ-Protokolle immer dann, wenn es um zuverlässige Datenübertragungen zwischen Peer-Entities geht. Sie werden daher meistens in der Link- oder in der Transport-Ebene innerhalb des OSI Modells der ISO eingesetzt. Inwieweit und unter welchen Bedingungen dieses “zuverlässig” gilt und welche Unterschiede die Protokolltechniken aufweisen, wird in den nächsten Laborterminen genauer untersucht.
Grundlegende Voraussetzung für den Block C des Praktikums sind Kenntnisse in der formalen Beschreibungssprache SDL.An dieser Stelle wird nicht näher auf SDL eingegangen. Eine mehr an die Entwicklungsumgebung SDT angelehnte Einführung in SDL liefern die SDT Dokumentationen in Kapitel 2.
Die Entwicklungsumgebung SDT ist eine Ansammlung von Werkzeugen, die alle unter einer einheitlichen grafischen Benutzeroberfläche integriert sind. Die Bedienung des Programmpakets lässt sich in vielen Situationen intuitiv erfassen. Für das Verständnis wofür die einzelnen Werkzeuge eingesetzt werden und wie ihr Zusammenspiel aussieht, ist es allerdings erforderlich, sich mit dem Handbuch auseinanderzusetzen. Die in den Literatur-Tabellen mit “obligatorisch” gekennzeichneten Abschnitte sind unbedingt zu lesen, die anderen Abschnitte erleichtern das Verstehen, z.B. durch Tutorien oder sind in ihrer Darstellung etwas ausführlicher. Dort werden auch Themen behandelt, die für die Lösung der Praktikumsaufgaben nicht unbedingt erforderlich sind, aber helfen die Arbeit mit SDT zu vereinfachen
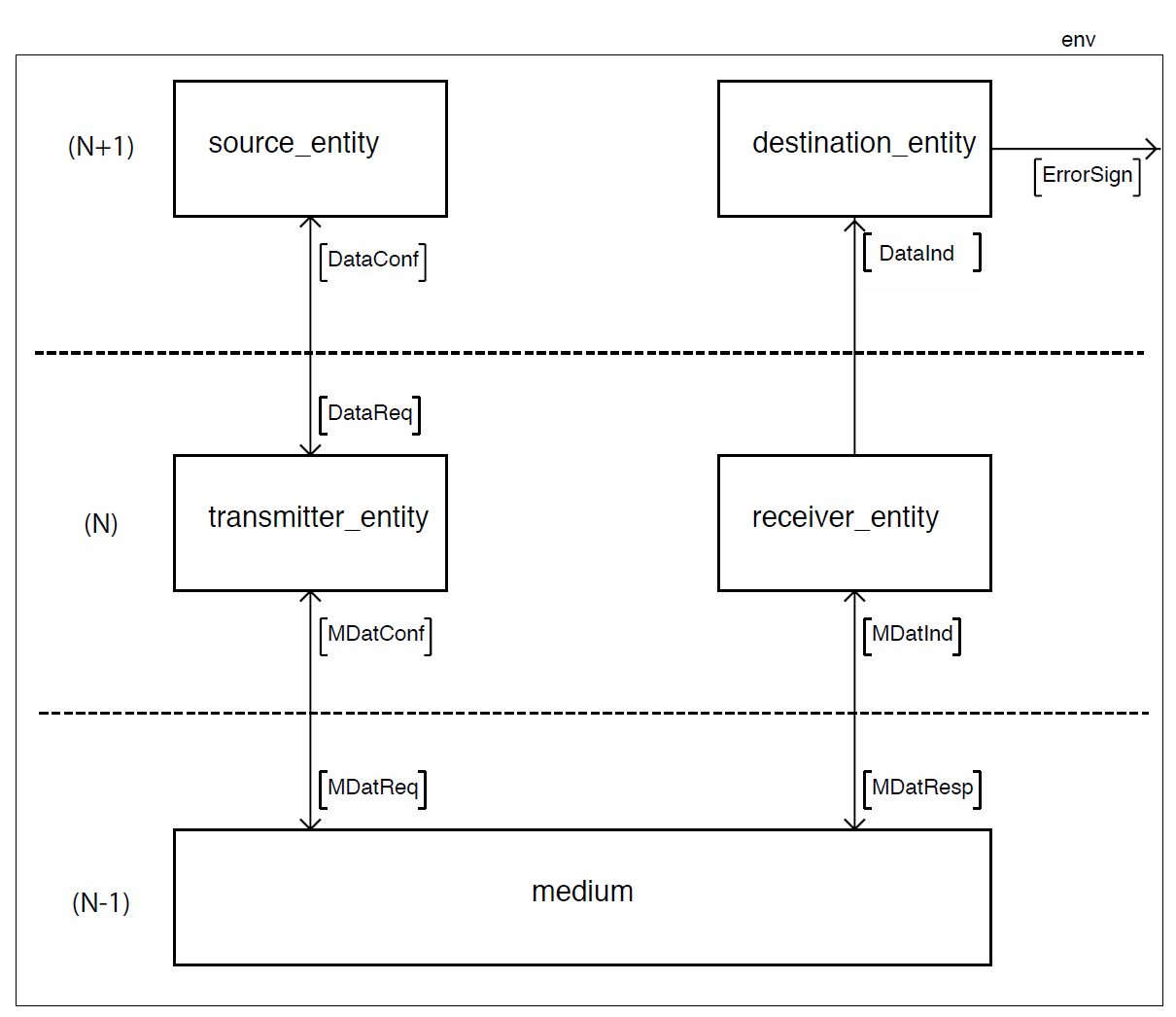
Für die anstehenden Aufgaben soll ein vorhandenes Kommunikationssystem benutzt werden, das an das OSI Modell angelehnt ist. Dieses System ist modular aufgebaut und besteht aus den Modulen source, transmitter, medium, receiver und destination (siehe Abb. 1). Hierbei stellen source und destination die Anwendungen der Schicht (N+1) dar, die Daten austauschen möchten. transmitter und receiver bilden die eigentliche Protokollschicht (Schicht (N)). medium ist der darunter liegende Transportservice der Schicht (N-1), der für Simulationen so eingestellt werden kann, dass er entweder zuverlässig oder unzuverlässig funktioniert.
Abb. 1: Framework
Die Übertragung der Nutzdaten erfolgt im vorliegenden Framework unidirektional: von source zu destination. Ein Verbindungsaufbau und -abbau, sowie ein automatischer Abbruch der Verbindung bei n vergeblichen Versuchen ein Paket zu übermitteln, werden in diesem Framework nicht modelliert.
Damit die Schichten, insbesondere die zwei jeweils beteiligten Prozesse, miteinander kommunizieren können, müssen passende Schnittstellen spezifiziert werden. Über die Schnittstellen werden Signale zwischen zwei Prozessen übermittelt. Die Festlegung der über die Signale ausgetauschten Datenformate stellt dabei nur einen Teil der Schnittstellenspezifikation dar. Zusätzlich müssen in SDL Regeln definiert sein, welche Signale es gibt und was sie bedeuten. Zusätzlich muss entsprechend des OSI Modells ein Service Access Point (SAP) bereitgestellt werden. Das geschieht in SDL z. B. durch Spezifikation der Signal-Routen. Für die Signale zwischen Anwendungsschicht (N+1) und Protokollschicht (N) wurde folgendes Format festgelegt:
newtype IDUType
struct
data DataType;
bool Boolean;
endnewtype IDUType;
}
Listing 1: SDL Darstellung einer Interface Data Unit (IDU)
wobei mit der Komponente data die Nutzdaten und mit bool Schnittstellensteuerinformationen transportiert werden können. Für die Kommunikation zwischen den Protokoll-Entities wird ein anderes Datenformat benutzt (siehe Listing 2 bzw. vgl. Abb. 9):
newtype PDUType
struct
seqno Natural;
data DataType;
acknakBoolean;
endnewtype PDUType;
}
Listing 2: SDL Darstellung einer Protocol Data Unit (PDU)
wobei auch hier die Komponente data für die Übermittlung der Nutzdaten vorgesehen ist. Darüber hinaus können Protokollsteuerinformationen wie Sequenznummer und/oder Empfangsquittung (Komponenten: seqno und acknak) ausgetauscht werden. Da die Schnittstellen zwischen den Modulen definiert sind, lassen sich die Inhalte der Module relativ leicht austauschen. Auf diese Weise kann man ein und dasselbe Kommunikationssystem für verschiedene Protokolle bzw. Protokollvarianten benutzen - es müssen einfach nur die Inhalte der Module transmitter und receiver ausgetauscht werden.
In diesem Kapitel wird die Funktionsweise und das Zusammenspiel der einzelnen Blöcke und Prozesse erläutert. Die entsprechenden Variablennamen, Signale, Zustände etc. sind in den entsprechenden SDL-Diagrammen dargestellt, welche sie rechts in der Menüleiste unter "SnW" oder hier finden können.
source
Die in der Anwendungsschicht unidirektional versendeten Nutzdaten . Die
source generiert hierbei mit einem einstellbaren Takt (
s_clk) eine Folge natürlicher Zahlen von “
1” beginnend aufwärts. Jede Zahl wird einzeln an das Modul transmitter gesendet (Signal
DataReq). Wenn der transmitter bereit ist, ein weiteres Signal
DataReq von der source entgegenzunehmen, dann sendet er das Signal
DataConf mit dem Parameterwert “
True” zurück; ist er nicht bereit, weitere Signale
DataReq entgegenzunehmen, dann verwirft er das nächste ankommende Signal
DataReq und antwortet mit dem Parameterwert “False”. Die
source wiederholt dann das letzte Signal
DataReq solange, bis sie ein Signal
DataConf mit einem “
True” erhält und die nächste natürliche Zahl versenden darf (siehe
source_process).
transmitter
Im
transmitter-Modul ist die Sendeseite des jeweiligen Kommunikationsprotokolls enthalten. Hier werden die von der source mit dem Signal
DataReq gesendeten Daten entgegengenommen, “verpackt” und mit dem Signal MDatReq dem Transportservice medium übergeben. Das Signal
MDatReq ist dabei so definiert, dass es neben den Nutzdaten auch eine Sequenznummer transportieren kann, wenn dies vom Protokoll vorgesehen ist (siehe
PDUType). Die Antworten der Empfängerseite werden durch das medium mit Hilfe des Signals
MDatConf signalisiert. Dieses Signal kann außer der Sequenznummer ein Flag besitzen, das anzeigt, ob es sich hierbei um eine positive oder negative Quittung handelt (
1=ACK, 0=NAK).
medium
Der Block medium repräsentiert den der Protokollschicht untergeordneten Transportservice der Schicht (N-1). Das medium arbeitet mit einer einstellbaren Taktgeschwindigkeit (m_clk bzw. r_clk) und funktioniert je nach Einstellung zuverlässig oder unzuverlässig. Die Fehlerarten, die hierbei im medium auftreten können, sind:
- Verlust (lose)
- Verdopplung (duplicate - kurz dup
- Vertauschung (reorder)
Im Block medium sind vier Prozesse enthalten (siehe Abb. 14 bis Abb. 24). Die Prozesse message_manager und response_manager übernehmen die „Durchleitung“ der Signale durch das medium. Wenn sie dabei nicht durch irgendwelche Signale der hazarddemons “gestört” werden, dann läuft das medium im reliable mode, d.h. es treten keine Fehler im medium auf. Ansonsten versenden die Prozesse msg_hazarddemon und resp_hazarddemon je nach Einstellung der zu generierenden Fehlerart in periodischen Abständen (MsgLose, MsgDup, MsgReord, RespLose, RespDup bzw. RespReord) an den jeweiligen Manager- Prozess.
Dieser behandelt dann die nach der Verarbeitung dieses Fehler-Signals eintreffenden Nachrichten vom transmitter (MDatReq) bzw. Antworten vom receiver (MDatResp) entsprechend.
Trifft z.B. ein MsgLose beim message_manager ein, dann verwirft er einfach das nächste Signal MDatReq. Bei einem MsgDup schickt er dem receiver zwei mal das gleiche Signal MDatInd. Da die im Block medium enthaltenen Prozesse Input-Queues besitzen (wie alle Prozesse in SDL), kann es vorkommen, dass sich mehrere Nachrichten gleichzeitig im medium befinden. Nur wenn das der Fall ist, funktioniert auch das Vertauschen von Nachrichten - der message_manager schickt dabei kein MDatInd an den receiver, sondern ein MDatReq an sich selbst bzw. an die eigene Input-Queue. Auf diese Weise wird dieses MDatReq verzögert (Delay). Sind dann noch andere MDatReq-Signale in der Input-Queue des message_managers, dann kommt es zu Überholungen (Reordering).
Im Block C wird ein erster Einblick in die Benutzung von SDT vermittelt. Neben der Bedienung der Benutzeroberfläche wird geübt, wie man ein modelliertes System simulieren und beobachten kann. Des weiteren soll untersucht werden, wie ein in SDL spezifiziertes Kommunikationssystem, das für den Datentransport das “Sendand- Wait”-Protokoll benutzt, sich bei sicherer und bei unsichererÜbertragung verhält.
Die folgende Beschreibung dieses Protokolls soll als Grundlage bzw. Referenz für die Bearbeitung der Aufgaben des ersten Termins dienen, wobei an dieser Stelle darauf hingewiesen wird, dass bei Tanenbaum und Halsall geringfügige Unterschiede existieren.
Im Folgenden wird nun kurz in Stichworten der Ablauf des Protokolls für eine unidirektionale (Nutz-)Datenkommunikation skizziert. Das „Send-and-Wait“-Protokoll verwendet dabei keine Sequenznummern zur Unterscheidung der einzelnen Datenpakete.
Zunächst soll die Benutzeroberfläche von SDT kennengelernt werden. Eine hierzu notwendige Vorstellung vom Grundkonzept des SDL-ToolSets SDT und ein erster Überblick über die einzelnen ”User Interfaces“ (UIs) sind in der SDT-Dokumentation erhalten. Anschließend wird der Umgang mit den UIs im Organizer und im SDL-Editor geübt.
Anschließend öffnen Sie durch einen Doppelklick den receiver_process im SDL-Editor. Notieren Sie sich die möglichen Ereignisse und die Namen der Zustände, den der Prozess annehmen kann. Schließen Sie anschließend wieder den Editor.
In einem nächsten Schritt öffnen Sie die Prozesse im Medium und bestimmen die Verzögerungszeit des Mediums und die Zeit zwischen zwei Fehlern.
Nachdem die Struktur des SnW-Systems bekannt ist, soll nun sein Verhalten betrachtet werden. Für die Untersuchung des Verhaltens eines modellierten Systems gibt es in SDT viele verschiedene Möglichkeiten. Im Rahmen dieses Laborpraktikums werden nicht alle davon verwendet.
Die gebräuchlichsten Funktionen zur Untersuchung des Verhaltens eines Systems stellt der Simulator zur Verfügung. Er bietet neben einem kontrollierbaren Ablauf des Systems (Step-by-Step oder bis zu einem Abbruchkriterium) vielfältige Beobachtungs- und Manipulationsmöglichkeiten. So lässt sich zum Beispiel mit Hilfe des so genannten MSC-Trace die Interprozesskommunikation (d.h. das Versenden und Empfangen von Signalen) in beliebigen Bereichen des Systems beobachten und aufzeichnen. Des Weiteren können mit Hilfe des Simulators Variablen, Timer, States und Input-Queues beobachtet und manipuliert werden.
Nach dem Start des Simulators werden die einzelnen geladen aber noch nicht gestartet („Start-State“). Erst wenn der Simulator in Gang gesetzt wird, dann wird für alle Prozesse die so genannte “Start-Transition“ durchgeführt, also der Übergang vom Start in den ersten Zustand des Prozesses. Bei diesem Vorgang werden auch die zum Prozess gehörenden Variablen initialisiert, d.h. auf den spezifizierten Anfangswert gesetzt. Ist kein Anfangswert explizit angegeben, dann wird die Variable mit „
0“ bzw. „
False“ initialisiert. Da die Variablen also erst bei der Start-Transition ihren Anfangswert erhalten, hat es keinen Sinn, sofort nach dem Start oder Restart des Simulators (Befehl
Restart im Menü File) irgendwelche Variablenwerte zu ändern - diese Werte werden bei der Initialisierung wieder überschrieben. Um eine Variable in einem bestimmten Prozess zu ändern, muss erst der „
Scope“ auf diesen Prozess gesetzt werden (Befehl „
Set Scope“ im Menü „
Examine“). Damit wird der Prozess ausgewählt, in dem die gesuchte Variable enthalten ist. Einzelne
Transitionen können mit dem Button Transition im Modul Execute ausgeführt werden. Einen Überblick über die noch anstehenden (Start-)Transitionen wird durch dem Befehl „
Ready Q“ im Menü „
Examine“ gegeben.
Übung 2: Initialisieren des Simulators (10 min):
- Simulator starten
- „Ready Q“ anschauen
- eine Variable mit Initialwert, der verschieden von Null ist, beobachten (z.B. Variable d in der source);
- (Start-)Transitionen durchführen
- „Ready Q“ anschauen
- Variable beobachten
- Simulator Restart
- Variable vor den Start-Transitionen auf einen Wert verschieden vom Initialwert ändern
- (Start-) Transitionen durchführen
- „Ready Q“ anschauen
- Variable beobachten.
Als nächstes wird eine Möglichkeit vorgestellt, wie man relativ einfach das Verhalten des gesamten Systems oder von Teilbereichen beobachten kann. Mit dem Befehl „MSC Trace:Start“ im Menü Trace wird ein „interaktives MSC-Log“ gestartet (siehe Abb. 5), auch MSC-Trace genannt. Auf diese Weise werden alle beobachtbaren Signalisierungen in Form eines MSCs protokolliert. Interaktiv ist dieses MSC-Log, weil man zu jeder Zeit das MSC editieren kann und die Auswirkungen von Änderungen, die der Benutzer am simulierten System zur Laufzeit vornimmt, sofort beobachtbar sind. Die „online“- Editiermöglichkeit ist hier sehr nützlich, da die im MSC-Editor dargestellten Prozesse nach dem Start des MSC-Logs oft erst in eine übersichtlichere Reihenfolge gebracht werden müssen (einfach mit der Maus ziehen, wobei man sich am Seitenbeginn befinden muss). Welche Instanzen (Prozesse und Blöcke) überhaupt beobachtet werden, lässt sich mit dem Befehl „MSC Level:Set“ im Menü Trace für jede Instanz festlegen. Wird für eine Instanz kein expliziter TraceLevel-Wert angegeben, dann orientiert sich der Simulator am TraceLevel-Wert der Instanz, die diese Instanz referenziert, d.h. in der Systemstruktur direkt übergeordnet ist. Bei einem Level-Wert von „0“ wird die jeweilige Instanz nicht beobachtet, d.h. sie taucht im MSC gar nicht erst auf, was erheblich zur Übersichtlichkeit beitragen kann. Da die Transitionen der gerade nicht beobachteten Instanzen aber natürlich trotzdem ausgeführt werden, kommt es dann nicht bei jedem Betätigen des Transition-Buttons zu einem Fortschreiben des MSC-Logs.
Übung 3: Einschalten der MSC Aufzeichnung (10 min)
- Set MSC-Level für das SnW- System auf 3 (Block Trace)
- Start MSC-Trace
- etliche Transitionen
- Stop MSC-Trace
- Exit MSC-Editor (NoSave)
Wenn im Menü „Execute" des Simulator UIs auf den Button Go geklickt wird, dann fängt die Simulation des Systems an zu laufen, d.h. alle jeweils anstehenden Transitionen werden automatisch ausgeführt. Anhalten kann man die Simulation auf zwei verschiedene Arten: per Hand (Button Break) oderautomatisch bei Erfüllung einer vorher festgelegten Abbruchbedingung, dem sogenannten “Breakpoint”. Es gibt verschiedene Arten von Breakpoints:
- Output-Breakpoint: Der “Output-Breakpoint” wird beim Versenden eines festgelegten Signals ausgelöst (Befehl „Output“ im Menü „Breakpoint“). Angegeben werden muss der Name des Signals, das beim Versenden die Simulation unterbrechen soll, der Prozess, der dieses Signal sendet und der Prozess, der das Signal empfängt. Zusätzlich kann für den sendenden und empfangenen Prozess eine bestimmte Inkarnation angegeben werden. Nur wenn diese Instanz das Signal versendet, wird dieSimulation angehalten. Man kann hier auch festlegen, dass der Breakpoint erst beim n-ten Auftritt dieses Signals ausgelöst wird.
- Variable-Breakpoint: Der „Variable-Breakpoint” wird ausgelöst, wenn sich der Wert der angegebenen Variable ändert (Befehl „Variable´“ im Menü „Breakpoint“). Beim Einrichten des Breakpoints bietet der Simulator eine Liste zu beobachtender Variablen an. Per Mausklick wird nun die gewünschte Variable ausgewählt. Wird die gewünschte Variable nicht angezeigt, muss zunächst der Scope auf den entsprechenden Prozess gesetzt werden, in dem die Variable definiert ist (Befehl „SetScope“ im Menü „Examine“).
- Symbol-Breakpoint: Ein weiterer interessanter Breakpoint ist der „Symbol-Breakpoint“. Dieser wird ausgelöst, wenn der Simulator beim Ablauf ein zuvor festgelegtes SDL-Symbol erreicht. Dazu wählt man im Menü „Breakpoint“ den Befehl „Connect sdle“ aus. Anschließend kann man dann im SDL-Editor das gewünschte Symbol markieren und mit dem Befehl „Set Breakpoint“ im Menü „Breakpoint“ des SDL-Editors das SDL-Symbol festlegen bei dem ein Breakpoint eingerichtet werden soll.
Übung 4: Breakpoints
Anhand der folgenden Befehle soll die Handhabung mit Breakpoints geübt werden:
- Go
- Break
- Set Output-Breakpoint auf das 5. MDatResp
- Go
- Remove OutoutBreakpoint
- Set Variable-Breakpoint auf Variable idu (destination)
- Go
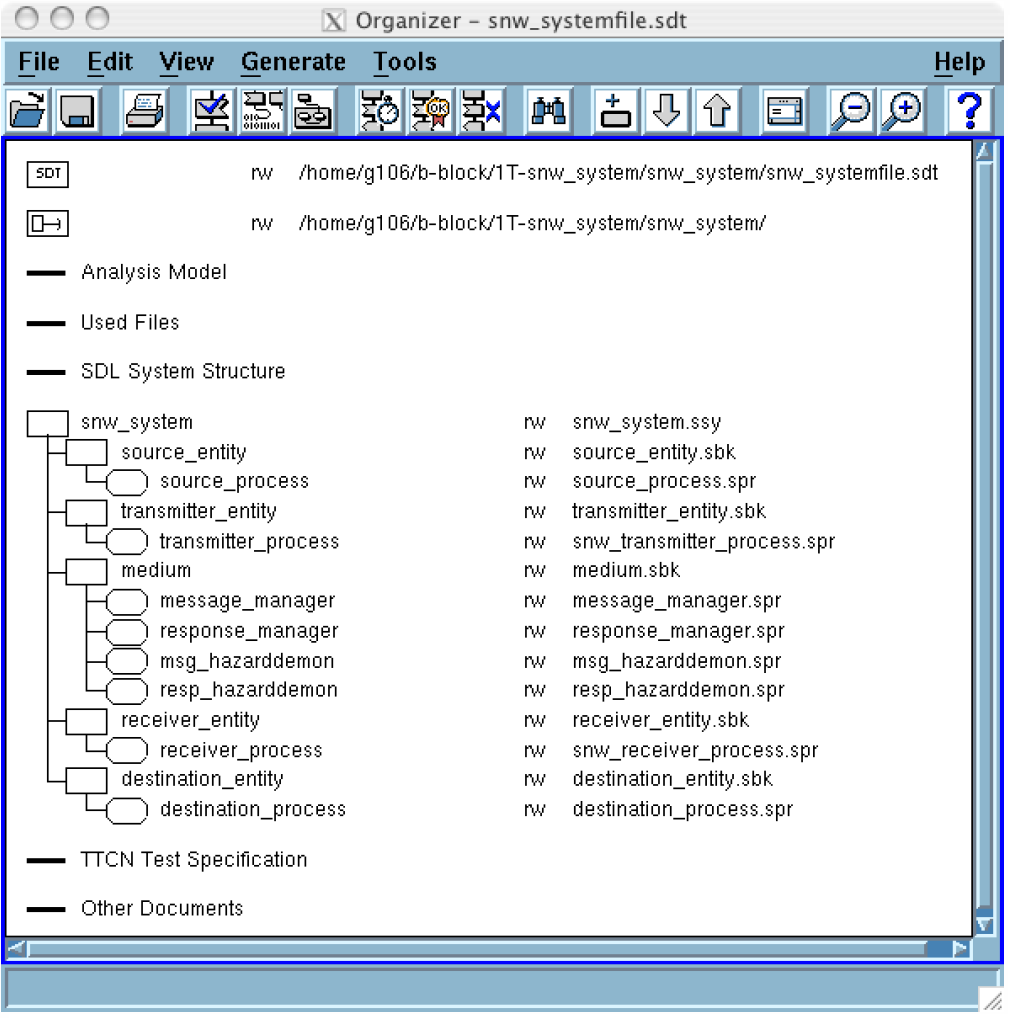
Nachdem das Organizer Fenster geöffnet wurde, findet man die Struktur in
Abb. 3 vor:
- Im Bereich „SDL System Structure“ befinden sich alle zum System gehörenden SDL-Blöcke mit den darin enthaltenen Prozessen.
- Direkt unter den SDL-Blöcken folgen Skripte.
In den sind Befehlsabläufe gespeichert. Sie dienen der Beschleunigung der Messungen und vereinfachen Ihnen die Konfiguration erheblich. In unserem Fall wurden Skripte vorbereitet, die das Verhalten des „Send-and-Wait“-Protokolls unter verschiedenen Fehlern im Medium (Skripte: packet_reliable, packet_lose, packet_reorder und packet_duplicate) mittels des Simulators analysieren. Durch Doppelklick auf eines dieser Skripte öffnet sich der SDL-Editor,
um den Inhalt anzuzeigen und editieren zu können.
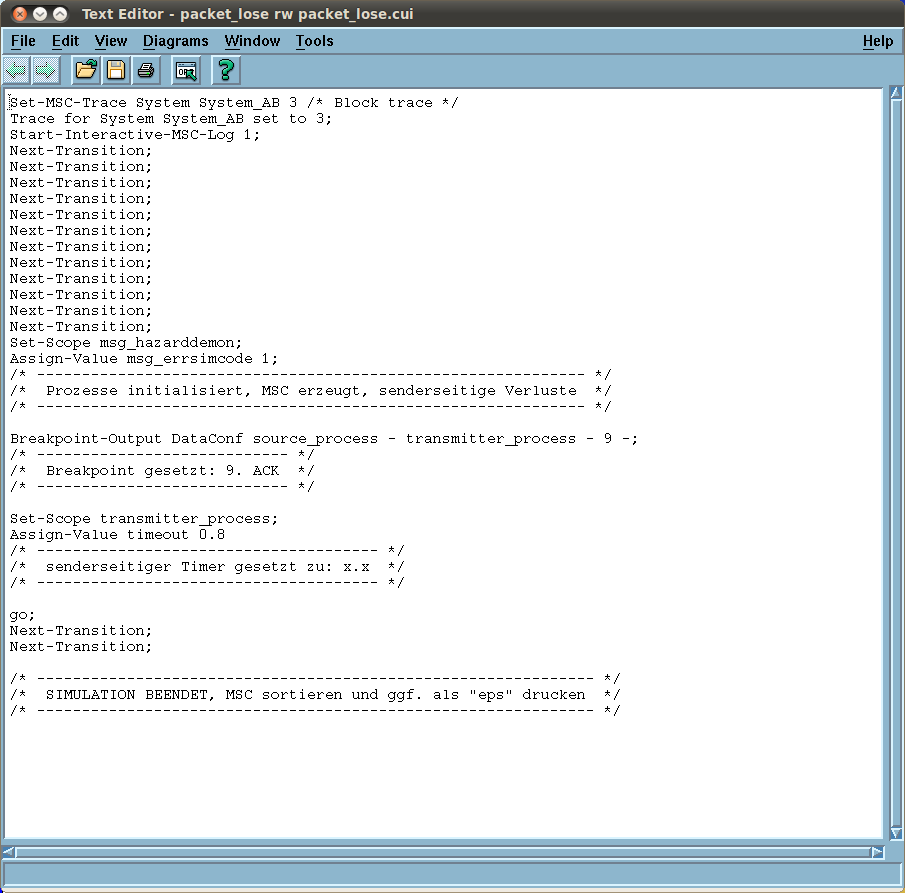
Abb. 6: Inhalt eines Skriptes packet_lose
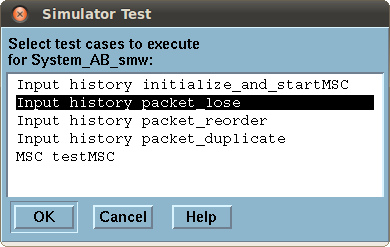
Abb. 6 zeigt beispielhaft den Aufbau des Skripts packet_lose. Wie in Abb. 6 zu erkennen ist, sind im Skript genau die Befehle enthalten, die in den vorangegangenen Abschnitten verwendet wurden. Beispielsweise wird der Befehl „Next-Transition;“ verwendet um die Start-Transition von allen im System enthaltenen Prozessen ausführen zu lassen. Anschließend wird der Wert der Variablen msg_errs des Prozesses msg_hazarddemon verändert. Bevor die Simulation mit dem „Go“-Befehl gestartet wird, wird ein Breakpoint gesetzt, damit die Simulation nicht endlos läuft. Zum Ausführen eines Skriptes ist das Skriptmittels rechtem Mausklick zu markieren. Im sich öffnenden Menü ist unter „Simulator Test“, dann „Existing Simulator...“ anzuklicken und das aktuelle System auszuwählen. Hierauf öffnet sich das Fenster zur Auswahl des Skripts (siehe Abb. 7).
Abb. 7: Auswahl des zu verwendenden Skriptes
Nachdem das Skript ausgewählt wurde, startet die Ausführung sofort. Sobald das „Organizer Log“ Fenster im Vordergrund erscheint, ist das Skript erfolgreich ausgeführt worden.
Beim Entwickeln einer Protokollsoftware stellt sich die Frage, mit welcher Protokolltechnik die angestrebte QoS sichergestellt werden kann. Dazu ist es erforderlich, verschiedene Protokolltechniken anhand einheitlicher Kriterien miteinander zu . Zwei Kriterien, die großen Einfluss auf die QoS-Parameter (Error Probability und Throughput) haben, sind hierbei Effektivität und Effizienz der Protokolltechnik. Unter Effektivität (auch: Robustheit, Resistenz) sollen hier die Fähigkeiten der Protokolltechnik verstanden werden, auftretende Fehler zu erkennen und zu beheben, d.h. alle entgegengenommenen Daten in der richtigen Reihenfolge, lückenlos und ohne Verdoppelungen auszuliefern. Hinter Effizienz verbirgt sich die Fragestellung, wie gut das Protokoll die vorhandene Bandbreite im Übertragungskanal ausnutzt (siehe Halsall [2]). Oder anders formuliert: Wie schnell kann mit diesem Protokoll (bei gegebener Bandbreite) eine bestimmte Menge Daten übertragen werden. Für die Bearbeitung der folgenden Aufgabe soll für das Effizienzkriterium diese zweite Definition benutzt werden.
Es sind Simulationen für den „reliable mode“ und für alle 6 im Medium-Service auftretenden Fehlerarten durchzuführen:
Bei welchen Fehlerarten kommt es zu Fehlern im von der destination empfangenen Datenstrom und was sind das dort für Fehler?
Mit Hilfe des Simulators soll die ermittelt werden, die das „Send-and-Wait“- Protokoll benötigt, um 50 Datenpakete zu übertragen - jeweils einmal für „reliable mode“, MsgLose, MsgDup und RespLose, RespDup. Zusätzlich ist jeweils der Wert der Variable errcnt aus dem destination-Prozess zu notieren. Die Ergebnisse sind hinsichtlich Effektivität und Effizienz des Protokolls bei Auftreten von unterschiedlichen Fehlern zu interpretieren.
Um die Messungen zu beschleunigen, bietet es sich an die vorbereiteten Skripte zu verwenden. Die Skripte stellen unter anderem die gewünschte Fehlerart ein und setzen einen Breakpoint auf das 50. Auftreten des Signals DataInd im destination Prozess.
Die Skripte modifizieren die Variable msg_errsimcode im Prozess msg_hazarddeamon. Durch die Modifikation der Variablen msg_errsimcode werden die Pakete (Daten) verdoppelt, zerstört usw. . Um die Quittungen (ACKs) zu modifizieren, sind keine Skripte vorhanden. Man kann zwei kleine Änderungen in den vorhandenen Skripten vornehmen, damit nicht die Pakete sondern die Quittungen (ACKs) modifiziert werden:
- Die Variable msg_errsimcode wird in die Variabel resp_errsimcode umgenannt.
- Damit der richtige Prozess gefunden wird, muss zusätlich der „Scope" auf den Prozess resp_hazarddeamon gesetzt werden. Dies wird darurch erreicht, dass die Zeile Set-Scope msg_hazarddemon; in Set-Scope resp_hazarddemon; geändert wird.
Die MSC-Logs („Block Trace“) der von „Send-and-Wait“ nicht erkannten Medium-Fehlerarten sollen gespeichert werden. Gehen Sie dabei wie folgt vor:
- Klicken Sie im MSC-Editor auf „File“
- Dann „Print...“
- Wählen Sie anschließend das gewünschte Dateiformat und den Speicherort aus.
- Am Besten ist hierfür das Dateiformat "eps" geeignet, da hierbei der gesamte Trace in einer einzelnen Vektorgrafik gespeichert wird. Mit dem von uns bereitgestellten Skript "eps2pdf_kn.sh (input.eps) [output.pdf]" kann diese Datei einfach in das pdf Format überführt werden. Alternativ können sie auch eine seitenweise Ausgbabe mit dem "ps" Dateiformat erhalten. Diese können sie mit "ps2pdf (input.ps) [output.pdf]" auf gleiche Weise in das pdf Format überführen. Es gibt außerdem auch die Möglichkeit eine png Datei (inklusive html zu Darstellung) zu erzeugen.
Zusätzlich sollen bei einer fehlerfreien Übertragung dieselben „Messungen“ für verschiedene Timeout-Werte im snw_transmitter durchgeführt werden. Auch hier sollen die Werte der Variablen now und errcnt ermittelt werden. Dabei sollen Werte für die Variable d verwendet werden die im Bereich 0.5 - 4 liegen
Ändern Sie für die Bearbeitung dieser Aufgabe den Wert d des Timers in den jeweiligen Skripten und führen diese anschließend aus. Die Ergebnisse sind bezüglich Effizienz und Effektivität des Protokolls bei unterschiedlichen Timerwerten zu interpretieren. Gibt es bei realen Anwendungen so etwas wie einen optimalen Wert für den „Retransmission Timer“?
Zur Vorbereitung arbeiten Sie bitte die Folien der Vorlesung für das „Go-Back-N“-Protokoll der Unit 10 (ARQ Approach) und dieses Kapitel durch.
Der Großteil der in diesem Kapitel aufgelisteten Anpassungen wurden bereits für Sie umgesetzt. Das gesamte System finden Sie in Ihrem Home-Bereich im Verzeichnis BlockC/ T2_GBNProtokoll und die wichtigsten Teile des Systems (Transmitter, TransmitterQueue und Receiver) im Skript. Der Transmitter kommuniziert mit dem Prozess TransmitterQueue, in dem die gesendeten Rahmen gespeichert werden bis sie quittiert werden (die RetransmissionQueue). Dieser Prozess braucht nicht beachtet werden und kann als gegeben vorausgesetzt werden. Außerdem braucht das Medium nicht näher untersucht werden, das eine Queue verwendet, in der Rahmen gespeichert werden, bis sie an den Receiver ausgeliefert werden. Damit das zur Verfügung gestellte System entsprechend der Spezifikationen des Protokolls funktioniert, müssen noch an 3 Stellen im SDL-Quellcode korrigiert werden.
Bei den bisher betrachteten Protokollen — „Send-and-Wait“ und „Alternating-Bit“ — befindet sich jeweils nur ein Paket im Medium: Nachdem der Sender ein Datenpaket versendet hat, wartet dieser auf eine Quittung vom Empfänger. Diese Vorgehensweise ist äußerst ineffizient, da der Kanal die meiste Zeit nicht belegt ist. Anstelle zu pausieren und nur auf die Quittung zu warten, könnten bereits weitere Pakete vom Sender übertragen werden.
Deshalb betrachten wir im folgenden Abschnitt das „Go-Back-N“- Protokoll. Grundsätzlich werden beim „Go-Back-N“- Protokoll Pakete gesendet ohne auf Quittungen (engl. Acknowledgement) der Pakete vom Empfänger zu warten. Diese kontinuierliche Übertragung von Paketen hat eine Erhöhung des Durchsatzes zur Folge, insbesondere dann, wenn eine geringe Bitfehlerwahrscheinlichkeit im Medium zu beobachten ist.
Dieses Kapitel wird zunächst einen Überblick über die allgemeine Funktionsweise des Protokolls geben. Anschließend wird eine analytische Leistungsanalyse zur Berechnung des Durchsatzes durchgeführt. Dadurch sind wir in der Lage, zu überprüfen, ob die Ergebnisse der anschließenden Experimente sinnvolle Ergebnisse zur Folge haben. Bei den Experimenten soll die Abhängigkeit des Durchsatzes von der Bitfehlerwahrscheinlichkeit im Medium und seine Abhängigkeit von der Fenstergröße näher analysiert werden.
Zu diesem Zweck enthält jeder Rahmen eine fortlaufende Sequenznummer. Erst, wenn die Anzahl der gesendeten Rahmen identisch mit der maximalen Fenstergröße ist, muss auf den Empfang einer Quittung gewartet werden. Eine Quittung vom Empfänger enthält eine Information darüber, wie viele Rahmen der Empfänger korrekt empfangen hat. Dieser Mechanismus hat zur Folge, dass der Durchsatz gegenüber dem „Alternating-Bit“-Protokoll ansteigt und gleichzeitig der Empfänger durch die eingebaute Flusskontrolle nicht überlastet wird.
In diesem Abschnitt gehen wir auf das grundlegende Verhalten des
Protokolls ein und nutzen die Beispiele aus Abb. 8 und Abb. 9.
Für die Funktionsweise des „Go-Back-N“-Protokolls wird zwischen zwei Fällen unterschieden:
- fehlerfreie Übertragung: In diesem Fall werden alle Datenpakete und deren Quittungen fehlerfrei übertragen.
- fehlerbehaftete Übertragung: Hierbei ist die Bitfehlerrate p>0. Es werden fehlerhafte Pakete und deren Folgepakete erneut übertragen.
Bei fehlerfreier Übertragung sendet der Sender kontinuierlich mit fortlaufenden Sequenznummern versehene Datenpakete über das Medium an den Empfänger. Der Empfänger quittiert korrekt empfangene Pakete mit der Sequenznummer des letzten erfolgreich und in korrekter Reihenfolge erhaltenen Paketes.
Beispiel:
Beim MSC in Abb. 8 stellt der gezeigte Fall die fehlerfreie Übertragung dar. Man erkennt, dass alle vom Sender verschickten Pakete im Abstand von \(t_I+t_p\) den Empfänger erreichen. Nach einer Verarbeitungszeit \(t_{proc}\) quittiert der Empfänger jedes korrekt empfangene Datenpaket mit einem Acknowledgment (kurz ACK), das nach der Zeit \(t_s+t_p\) vom Sender empfangen wird. Hierbei gilt, dass die Sequenznummer eines ACKs immer das letzte in korrekter Reihenfolge empfangene Paket des Senders beinhaltet. Nach dem ersten empfangenen Paket ist dies "0", dann "1, "2", usw.
Anmerkung:
- \(t_I\) - beschreibt das Transmission-Delay eines Datenpaketes und
ist definiert als die Bitrate dividiert durch die Paketgröße.
- \(t_s\) - beschreibt das Transmission-Delay einer Quittung und ist
definiert als die Bitrate dividiert durch die Größe des Quittungs-
Paketes.
- \(t_p\) - beschreibt das Propagation-Delay.

Abb. 8: Message Sequence Chart (MSC) für den fehlerfreien Fall, für das GBN-Protokoll ohne Flusskontrolle
Wie beim „Alternating-Bit“- oder „Send-and-Wait“-Protokoll, startet der Sender des „Go-Back-N“-Protokolls auch einen Retransmission-Timer für jedes versendete Paket. Läuft der Timer vor Erhalt der Quittung ab (z. B. durch Verlust eines Pakets im Medium), werden alle Pakete ab jenem, für das der Timer abgelaufen ist, erneut übertragen.
Ähnlich verhält es sich, wenn eine Quittung verloren gegangen ist: Der Sender erhält nicht die erwartete Quittung - vor Ablauf des Retransmissiontimers - und überträgt alle bis zu dem Zeitpunkt unbestätigten Pakete erneut.
Anmerkung:
In der Regel werden kumulative Quittungen verwendet. Dies bedeutet, eine Quittung alle zuvor gesendeten Pakete auch quittiert. Hierdurch wird der Einfluss von verloren gegangenen ACK reduziert. Demnach interpretiert das Protokoll nicht am Sender erhaltene ACKs als empfangen, sobald das Acknowlegment eines späteren Pakets den Sender erreicht.
Beispiel:
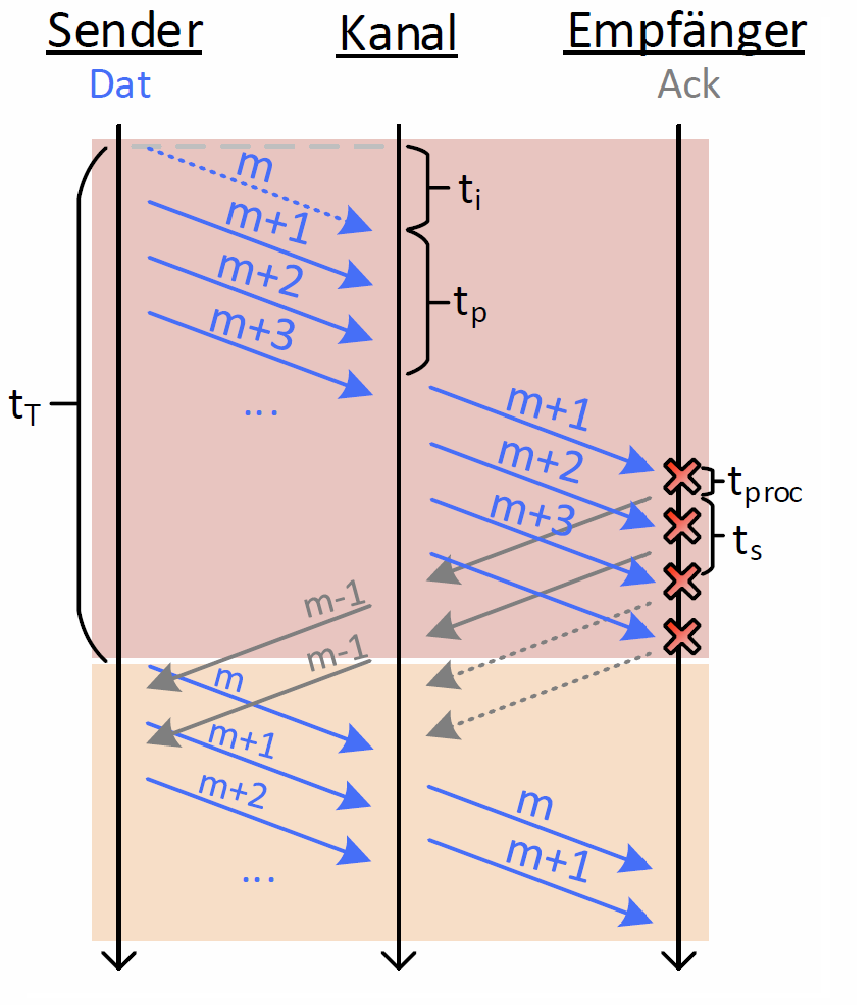
Beim MSC in Abb. 9. stellt der erste, farblich rot markierte Abschnitt den Fall der fehlerhaften Übertragung dar. Man erkennt, dass das Paket mit der Sequenznummer „m“ punktiert dargestellt ist und nicht den Empfänger erreicht, da es im Medium verloren gegangen ist. Alle folgenden vom Sender verschickten Pakete (mit den Sequenznummern „m+1“, „m+2“, usw.) erreichen den Empfänger fehlerfrei. Da das Paket mit der Sequenznummer „m+1“ nicht jener am Empfänger erwarteten „m“ entspricht, werden alle im Folgenden empfangene Pakete verworfen und mit der Quittung des letzten korrekten Paketes „m-1“ bestätigt. Erst nachdem der Retransmissiontimer für Paket „m“ nach tout abgelaufen ist, wird die erneute Übertragung aller unbestätigten Pakete gestartet. Dies ist der als Fehlerbehebung bezeichnete und orange markierte Abschnitt in Abb. 9..
Abb. 9: Message Sequence Chart (MSC) für den fehlerhaften (rot) Fall mit anschl. Fehlerbehebung (orange) für das GBN-Protokoll ohne Flusskontrolle
Literaturhinweis: Dieses Kapitel ist stark am Buch „Telecommunication Networks — Protocols, Modeling and Analysis“, Addison-Wesley, 1988 von Mischa Schwartz angelehnt. I.d.R. stammen die Formeln und Abbildungen aus diesem Werk.
Gesucht wird die Dauer, die im Mittel benötigt wird, um ein Paket erfolgreich zum Empfänger zu übertragen. Erfolgreich übertragen bedeutet hierbei, dass das Paket den Empfänger fehlerfrei und in korrekter/erwarteter Reihenfolge erreicht.
Wie bei der Beschreibung der Funktionsweise des "Go-Back-N"- Protokolls (siehe Kapitel 4.1), wird bei der Herleitung der Dauer der mittleren Übertragungszeit eines Pakets zwischen der fehlerfreien und der fehlerbehafteten Übertragung unterschieden.
Zur Vereinfachung der Herleitung, werden die im Folgenden getroffenen Annahmen verwendet. Diese Vereinfachungen können dazu führen, dass die Ergebnisse der Herleitung zu abweichenden Ergebnissen gegenüber realen Experimenten führen:
- Die möglichen Sequenznummern einzelner Pakete seien nicht beschränkt.
- Keine negative Quittungen: Ein Paket wird erst erneut gesendet, wenn der Retransmission-Timer abgelaufen ist. Wurde zuvor eine Quittung empfangen, die vermuten lässt, das ein Paket nicht empfangen wurde, dann wird diese Quittung ignoriert.
- Die Verarbeitungsgeschwindigkeit des Empfängers \(t_{proc}\) ist zu vernachlässigen. Genauer: Sie ist sehr viel größer als die Übertragungsgeschwindigkeit des Kanals und die Verarbeitungsgeschwindigkeit des Senders. Dies bedeutet, dass keine Flusskontrolle (engl. Congestion Control) notwendig ist.
- Es liege in diesem Modell eine gesättigte Übertragung vor. Dies bedeutet, dass permanent Daten zur Übertragung seitens des Senders zur Verfügung stehen.
- Es seien alle Paketlängen und der Wert des Retransmission-Timers \(t_{out} = 2t_I + 2t_p \) konstant.
- Die Dauer zur Übertragung einer Quittung ts sei kleiner als die eines Pakets.
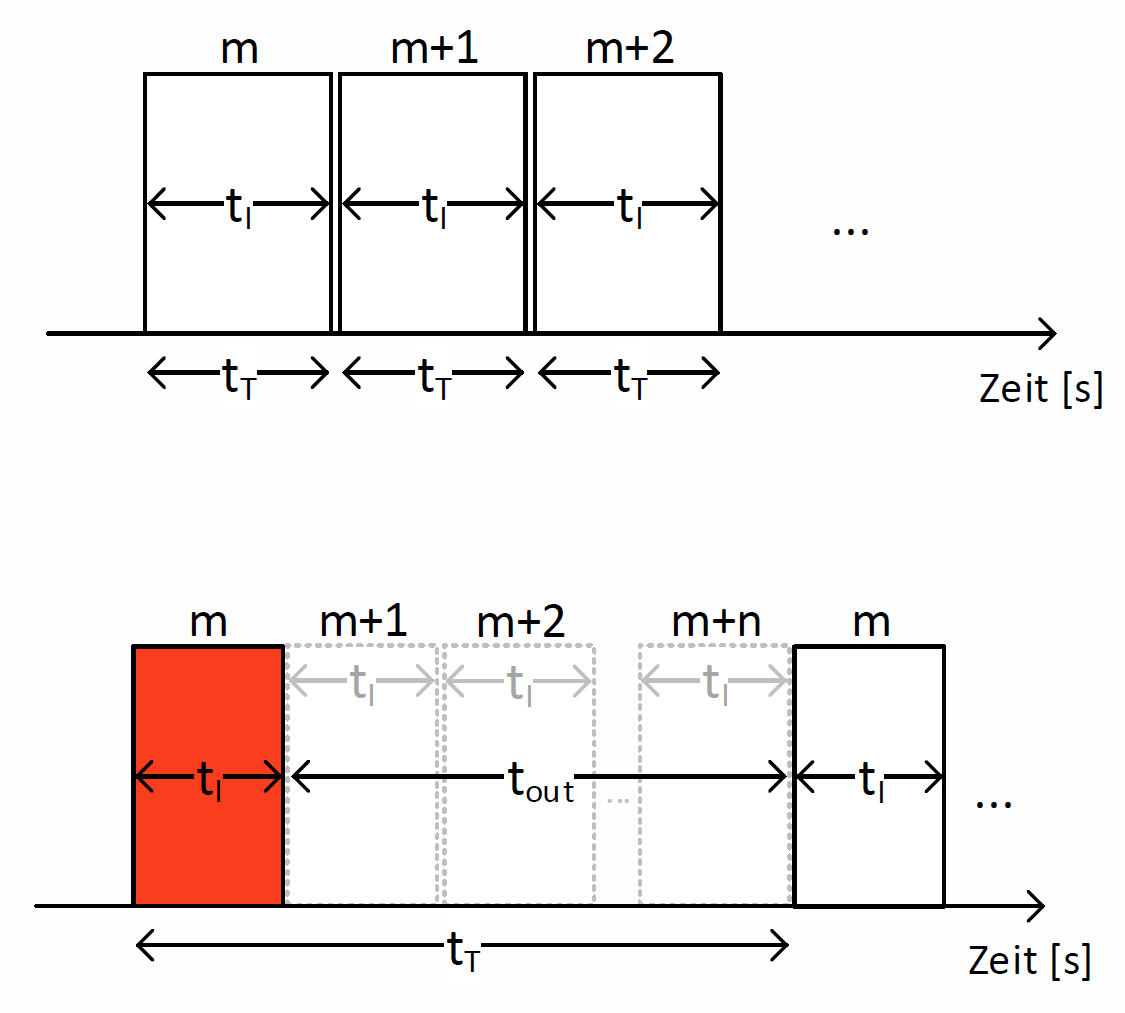
Abb. 10: GBN-Analyse für fehlerfreie Übertragung (oben) und fehlerbehaftete Übertragung (unten)
Der Wert \(t_T = t_I + t_{out}\) beschreibt die Dauer, die pro fehlerhaftem Übertragungsversuch vergeht, ehe die erneute Übertragung beginnt.
Mittlere Übertragungszeit eines Pakets im fehlerfreien Fall
Durch die kontinuierliche Übertragung benötigt jedes Paket die Dauer von \(t_I\) zur Übertragung. Da beim "Go-Back-N"-Protokoll nicht auf ein Acknowledgment gewartet wird, ehe das Folgepaket übertragen werden kann, beträgt die mittlere Übertragungszeit \(t_V\) eines Paketes im fehlerfreien Fall:
$$
t_V = t_I
\tag{1}
$$
Der maximal erreichbare Durchsatz (Pakete/Sekunde) berechnet sich nun aus dem reziproken Wert der mittleren Übertragungszeit. Es gilt folglich:
$$
D_{max} = \frac{1}{t_V} = \frac{1} {t_I}
\tag{2}
$$
Mittlere Übertragungszeit eines Pakets im fehlerbehafteten Fall
Die Bitfehlerwahrscheinlichkeit betrage nun p. Somit ist die Wahrscheinlichkeit dafür, dass ein Bit fehlerfrei übertragen wird gegeben als
$$
1-p
\tag{3}
$$
In diesem statistischen System mit der Bitfehlerwahrscheinlichkeit p, wird nun das folgendes Ereignis näher betrachtet: Die erste Übertragung eines Paketes ist mit der Wahrscheinlichkeit p fehlerbehaftet und/aber der zweite Versuch der Übertragung eines Pakets ist mit der Wahrscheinlichkeit (1-p) erfolgreich. Für dieses spezielle Ereignis wird die mittlere Übertragungszeit \(t_V\) gesucht.
Dieses spezielle Ereignis hat die Wahrscheinlichkeit \(p \cdot (1-p)\) und tritt immer dann ein, wenn der Sender für die Dauer des Retransmission- Timeout-Intervalls \(t_{out}\) auf das entsprechende Acknowledgment wartet. Danach kann der erste Übertragungsversuch der fehlerhaften Übertragung mit der Dauer \(t_T= t_{out}\) als abgeschlossen betrachtet werden.
Nachfolgend ist dann die Übertragung erfolgreich und hat die Dauer \(t_I\). Demnach ist die mittlere Übertragungszeit:
$$
t_V = \overbrace{t_I}^{erfolgreiche \ Übertragung} + \overbrace{\underbrace{(1-p)}_{Wahrscheinlichkeit \\ fehlerfreier \ Übertragung.} \cdot \underbrace{1p \cdot t_T}_{Wahrscheinlichkeit \ fehlerhafter \\ Übertragung \ inkl. \ Dauer}}^{Dauer \ einer \ fehlerhaften \ Übertragung}
\tag{4}
$$
Ist auch dieser erneute Übertragungsversuch fehlgeschlagen, dann erreicht ein Paket erst nach dem dritten Übertragungsversuch den Empfänger (bzw. das ACK den Sender), so erhöht sich \(t_V\) um den 3. Summationsterm in Gleichung (5) ehe das Paket erfolgreich den Empfänger erreicht.
$$
t_V = \overbrace{t_I}^{erfolgr. \ Übertr.} + \underbrace{(1-p) \cdot 1p \cdot t_T}_{Dauer \ der \ ersten \\ fehlerhaften \ Übertr.} + \underbrace{(1-p) \cdot 2p^2 \cdot t_T}_{Dauer \ der \ zweiten \\ fehlerhaften \ Übertr.}
\tag{5}
$$
Man erkennt hieraus bereits die folgende, allgemeine Bildungsvorschrift:
$$
t_V = \overbrace{t_I}^{(i+1)-te \ Übertragung \\ (erfolgreich)} + \overbrace{(1-p) \cdot \sum_{i=1}^{\infty} ip^i \cdot t_T}^{i \ Übertagungen \\ (fehlerhaft)}
\tag{6}
$$
Die mittlere Übertragungszeit für ein erfolgreich am Empfänger angekommenes Paket \(tV\) erhöht sich abhängig davon, wie oft es erneut übertragen werden muss
Wiederholung mathematischer Grundlagen: Wie eventuell noch aus den mathematischen Grundlagen-Modulen bekannt ist, handelt es sich hierbei um eine geometrische Reihe. Aufgrund dieser Tatsache, kann die Summe vereinfacht und dadurch ersetzt werden. Für geometrische Reihen gilt allgemein:
$$
(1-q) \cdot \sum_{k=0}^{\infty}q^k = 1 - q^{n+1}
\tag{7}
$$
Für q ungleich 1 lässt sich die Gleichung durch (1-q) teilen:
$$
\sum_{k=0}^{\infty} {q^k} = \frac{q^{n+1} -1 } {q-1} = \frac{1-q^{n+1}} {1-q} \\
\lim_{n \rightarrow \infty} \frac{1-q^{n+1}} {1-q} = \frac{1} {1-q}
\tag{8}
$$
Vorfaktoren — wie in unserem Fall tT — können problemlos aus der Summe gezogen werden.
Dennoch enthält unsere Folge zusätzlich die Gauß'sche Summenformel. Somit folgt für die mittlere Übertragungsdauer eines Paketes:
$$
\begin{align}
t_V &= t_{I} + (1-p) \cdot t_T \cdot \sum_{i=1}^{\infty}{ip^i} \\
&= t_{I} \cdot \left( \frac{1-p+\frac{t_T}{t_I}\cdot p}{1-p} \right) \\
&= t_I \cdot \left( \frac{1+(a-1) \cdot p}{1-p} \right), \ \ \ mit \ a = \frac{t_T}{t_I} \\
\end{align}
\tag{9}
$$
wobei p die Bitfehlerwahrscheinlichkeit und a=tT/tI beschreibt. Falls die Ausbreitungszeit tp und Verarbeitungszeit ts verglichen mit der Übertragungsdauer tI vernachlässigbar sind und somit a=1 gilt, entsprechen die Ergebnisse jenen vom SnW-Protokoll. Der reziproke Wert beschreibt den maximal möglichen Durchsatz. Es gilt:
$$
D_{max} = t_V^{-1} = \frac{1-p}{1+(a-1) \cdot p \cdot t_I}
\tag{10}
$$
wobei der normalisierte Durchsatz r für jede Paketankunftsrate D ist:
$$
\rho = D \cdot t_I < \frac{1-p}{1+(a-1) \cdot p}
\tag{11}
$$
Beispiel: Gegeben sei eine terrestrische Verbindung mit einer Kapazität von 9600 Bits/s und einer festen Paketlänge von 1200 Bits. Sei der Link kürzer als 160 km und sei das propagation delay etwa 1 ms/160 km, so ist das round-trip propagation delay maximal 2 ms.
Bestimmen Sie die Übertragungsdauer und dem idealen Wert für den Retransmission-Timer.
Lösung: \(t_I\) = 1200 b/9600 bps = 125 ms, \(t_{out} = 2 t_p + t_{proc} + t_s\)
Wie bereits zuvor beschrieben, sollte der Wert für \(t_{out}\) nicht zu klein gewählt werden. Es benötigt somit mindestens \( 2t_p+t_s\), bis eine Bestätigung den Sender erreicht. Werden die Bestätigungen in separaten Paketen gesendet, benötigt dieses zusätzlich \(t_I\). Um sicherzugehen, wird der Wert für \(t_{out}\) daher auf \(2t_p+2t_I\) gesetzt.
Somit folgt für die minimale Zeit zwischen zwei erfolgreich übertragenen Paketen: \(t_T=t_I+t_{out}=3t_I+2t_p\). Für \(a=\frac{t_T}{t_I}\) folgt \(3+\frac{2tp}{tI}\). Dieses kontinuierliche GBN-Protokoll führt somit zu einer Durchsatzerhöhung gegenüber dem einfachen Send-and-Wait Protokoll von a > 3.
In der folgenden Abbildung sind drei Verläufe des Durchsatzes über der Paketlänge dargestellt. Jede Kurve stellt dabei eine bestimmte Art der Übertragung dar (Sat, WLAN und LAN), die sich bezüglich ihrer Fehlerrate und Propagation-Delay unterscheiden.
Abb. 11: Durchsatz-Verläufe am Beispiel 3 charakt. Technologien
Beim in Kapitel 4.2 betrachteten Go-Back-N Protokoll wird das Medium in der Regel komplett ausgelastet. Hierdurch kann es vorkommen, dass der Empfänger oder das Netzwerk zeitweilig überlastet wird. Die unbeschränkte senderseitige Übertragung von Datenpaketen wird nun mithilfe der Flusskontrolle reguliert. Hierzu definiert das Go-Back-N Protokoll die Fenstergröße M, die die Anzahl der maximal vom Sender zu übertragenen Pakete an den Empfänger begrenzt. Beim Erreichen dieser Grenze, pausiert der Sender mit der Übertragung weiterer Pakete und wartet auf eine Quittung seitens des Empfängers.
Der fehlerfreie Fall
Im fehlerfreien Fall sendet der Sender M Datenpakete an den Empfänger, wobei M die Fenstergröße beschreibt. In Abb. 34, ist M=3, sodass der Sender erst auf eine Quittung seitens des Empfängers warten muss, ehe er weitere Pakete (n+3, n+4, ...) versenden darf.
Nach der Dauer \(t_{ack}\) erreicht den Sender die Quittung zum korrespondierenden Paket - in diesem Beispiel ist dies die Quittung für das Paket mit der Sequenznummer „n“ - sodass folglich das Folgepaket versendet werden darf. \(t_{ack}\) ist hierbei die Summe aus den Propagation-Verzögerungen für das Datenpaket und Acknowlegment (also \(2t_p\)) und der Verzögerung zur Übertragung eines ACK (\(t_s\)). Es gilt: \(t_{ack}=2t_p+t_s\). Da die Acknowlegments für die Pakete eines Fensters nahezu hintereinander den Sender erreichen, kann dieser nun auch wieder Folgepakete übertragen entsprechend der Fenstergröße.
Abb. 12: GBN-Protokoll mit Flusskontrolle für fehlerfreie Übertragung und der Fenstergröße 3
Die erfolgreiche Übertragung eines einzelnen Paketes beträgt \(t_I + t_p\). Somit beträgt die Übertragungsdauer für M Pakete abhängig der
Fenstergröße insgesamt \(M \cdot t_I + t_p\)
Im Vergleich zum Kapitel 4.2 limitiert nun die Fenstergröße M die maximale Anzahl zu sendender und unbestätigter Pakete.
Nachdem der Sender die maximal mögliche Anzahl an Paketen versendet hat, muss dieser mit der Übertragung pausieren und zwar solange, bis er eine Bestätigung seitens des Empfängers erhält. Die Dauer bis die Bestätigung den Sender erreicht beträgt \(t_s + t_p\). Der Einfachheit halber wird für ein ACK die identische Übertragungsdauer eines Datenpaketes verwendet (Quittungen haben aufgrund ihrer geringeren Paketgröße eine viel kürzere Übertragungsdauer), sodass \(t_s=t_I\) gilt.
In der Abb. 12 werden \(2t_p\) (1x für die Datenpakete und 1x für die Bestätigung) und \(t_s=t_I\) zu \(t_{ack}\) zusammengefasst. Somit erhält man für die mittlere Übertragungsdauer \(t_V\) pro Paket abhängig der Fenstergröße:
$$
t_V = \frac{M \cdot t_I + t_{ack}}{M} \ \ \ \ , \ mit \ t_{ack} = 2 \cdot t_p +t_I
\tag{12}
$$
Der Durchsatz berechnet sich aus dem reziproken Wert der mittleren Übertragungsdauer und es gilt:
$$
D = t_V^{-1} = \frac{M}{M \cdot t_I + t_{ack}} \ \ \ \ , \ mit \ t_{ack} = 2 \cdot t_p +t_I
\tag{13}
$$
Zur Überprüfung des Ergebnisses der Gl. (13) betrachten wir nun die Grenzfälle für eine extrem kurze Propagation-Verzögerung und jener, die ein Vielfaches höher als die Transmission-Verzögerung ist:
$$
\lim_{t_p \rightarrow 0} D = \frac{1} {t_I}
\tag{14}
$$
und
$$
\lim_{t_p \gg t_I} D = M \cdot \frac{1} {t_p}
\tag{15}
$$
Es zeigt sich:
Ist das Propagation-Delay vernachlässigbar (siehe Gl. (14)), erhält man das selbe Ergebnis wie für das Go-Back-N Protokoll ohne Flusskontrolle (siehe Kapitel 4.2). Bei hohem Propagation-Delay nimmt der Durchsatz linear mit steigender Fenstergröße zu (siehe Gl. (14)).
Der fehlerbehaftete Fall.
Die Bitfehlerwahrscheinlichkeit betrage nun erneut p>0. Analog zum fehlerbehafteten Fall ohne Flusskontrolle, verhält sich das System auch mit Flusskontrolle: Erreicht ein Datenpaket nicht den Empfänger, so wird der Sender keine Quittung für dieses Paket innerhalb des Timeout-Intervalls erhalten. Sobald der Retransmission-Timer abgelaufen ist, überträgt der Sender das gesamte Fenster erneut und wartet anschließend auf die Quittungen.
Daher ähnelt die Berechnung des Durchsatzes mit Flusskontrolle stark der Berechung des Durchsatzes ohne Flusskontrolle (siehe Gl. (6)).
Wir werden daher erneut den Durchsatz mit Hilfe der mittleren Übertragungsdauer eines Paketes, \(t_V\), bestimmen. Zusätzlich zur Dauer, die für die erfolgreiche Übertragung benötigt wird, erhöht sich \(t_V\) bei jedem fehlerhaften Übertragungsversuch:
Es wird vergeblich auf das entsprechende ACK gewartet, ehe die erneute Übertragung des Fensters beginnt. Analog zum Durchsatz ohne Flusskontrolle, können die fehlerhaften Übertragungsversuche durch eine geometrische Reihe beschrieben werden.
$$
t_V = \overbrace{\frac{M \cdot t_I + t_{ack}}{M}}^{erfolgreiche \ Übertragung} + \overbrace{ \sum_{n=1}^{\infty} n \cdot \underbrace{(1-p) \cdot p^n}_{Wahrscheinlichkeit} \cdot \underbrace{t_T(M)}_{Dauer}}^{n \ fehlerhafte \ Übertragungen}
\tag{16}
$$
Wie man deutlich in Gl. (16) erkennen kann, ist die Dauer einer fehlerhaften Übertragung, \(t_T\), nun abhängig von der Fenstergröße M.
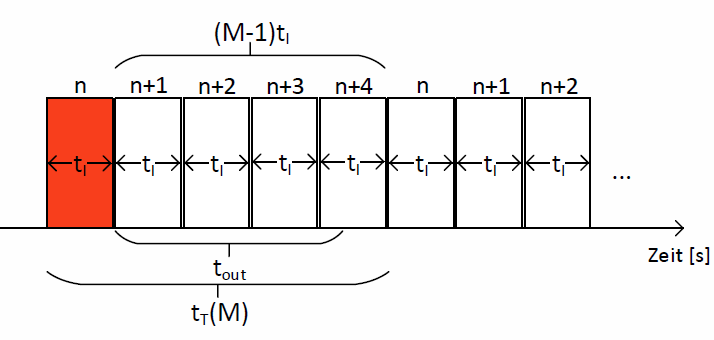
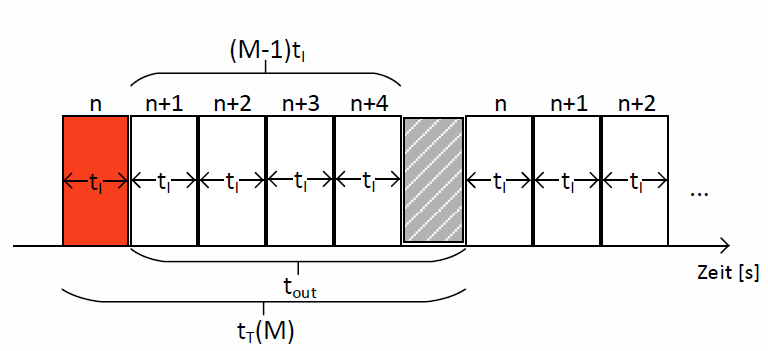
Aus diesem Grund wird zwischen zwei Fällen unterschieden. Die Dauer der fehlerhaften Übertragung tT variiert, je nachdem, ob der Retransmission-Timer bereits während der Übertragung des Fensters abläuft oder erst, nachdem das Fenster komplett versendet wurde.
Diese beiden Fälle werden wir nun genauer betrachten:
Nachdem wir nun die beiden möglichen Fälle für die Dauer, nachdem die erneute Übertragung eines Fensters beginnt, betrachtet haben, wissen wir, dass dieser Wert \(t_T\) grundsätzlich nicht nach oben beschränkt, wohl aber nach unten durch die Fenstergröße begrenzt ist. Um die oben genannte Formel für beide Fälle anwenden zu können, definieren wir \(t_T(M)\) zu dem höheren der beiden möglichen Werte. Es gilt:
$$ t_T(M) = max\{t_{out},(M-1) \cdot t_I\}
\tag{17}$$
Setzt man dies in die Gleichung von tV ein, so erhält man für die mittlere Übertragungsdauer pro Paket:
$$ t_V = \frac{M \cdot t_I + t_{ack}}{M} + \sum_{n=1}^{\infty} (1-p) \cdot p^n \cdot n \cdot (max\{t_{out},(M-1)t_I\}+t_I)
\tag{18}
$$
Für den Durchsatz gilt erneut der reziproke Wert der mittleren Übertragungsdauer:
$$ D_{max} = t_V^{-1}
\tag{19}
$$
Der relative Durchsatz berücksichtigt die Nutzdatengröße eines Rahmens und die vorhandene Bitrate des Links:
$$ \frac{D}{C} = \frac{D_{max} \cdot l }{C} = \frac{l}{t_V C}
\tag{20}
$$
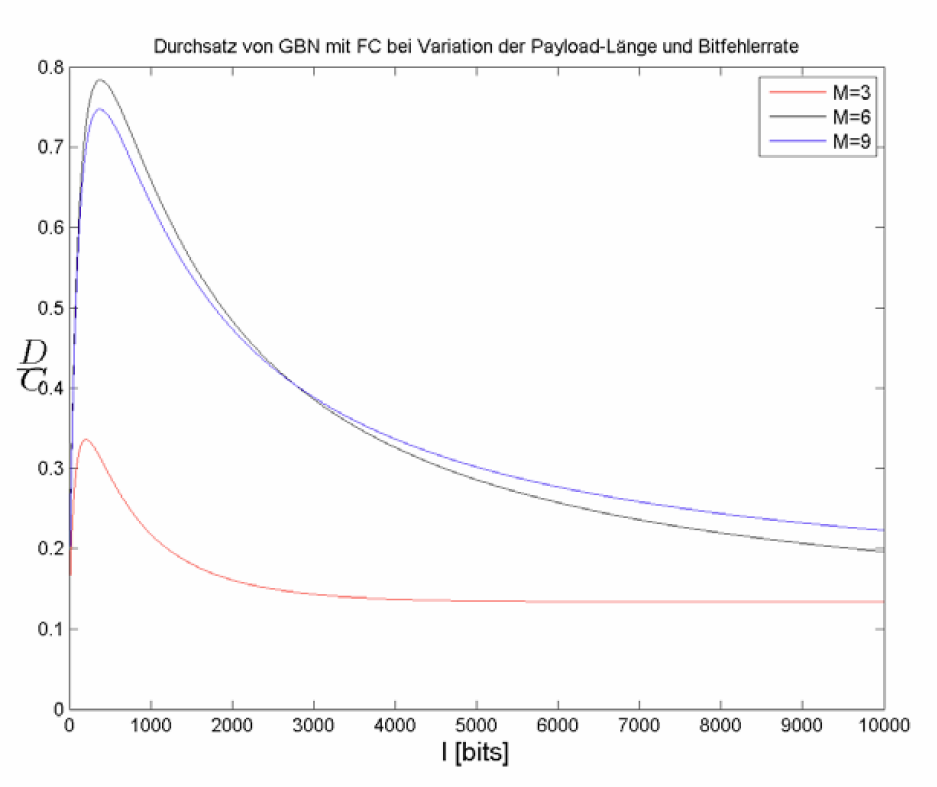
Abb. 15: Durchsatzverläufe mit Flusskontrolle bei Variation der Fenstergröße
Wie bereits Abb. 11 im Fall ohne Flusskontrolle, visualisiert Abb. 15 die erreichbaren Durchsatzraten.
Entsprechend der kurzen Beschreibung des „Go-Back-N“-Protokolls ist ersichtlich, welche Modifikationen beim „Alternating-Bit“-Protokoll durchgeführt werden müssen damit daraus ein Go-Back-N Protokoll wird:
- Es muss eine Konstante MaxWindow eingeführt werden, die den Wert der maximalen Fenstergröße (engl. window size) angibt.
- Es muss eine Variable eingeführt und initialisiert werden, die den Wert der augenblicklichen Fenstergröße symbolisiert. Window gibt an, wie viele unquittierte Pakete noch versendet werden dürfen.
- Es muss die Variable NS im Transmitter eingeführt werden, die die Nummer des nächsten zu sendenden Rahmens angibt. Die Variable NR des Transmitters gibt die Nummer des letzten in korrekter Reihenfolge empfangenen Rahmens an. Die Differenz zwischen NS und NR ist die Anzahl der Rahmen, die sich auf dem Weg zwischen Sender und Empfänger befinden.
- Es muss die Variable VS eingeführt werden. Eine Quittung des Empfangers enthält die Rahmennummer VS, die der nächste Rahmen des Senders haben muss bzw. von ihm erwartet wird.
- Das folgende Beispiel im fehlerfreien Fall soll diese Verhalten veranschaulichen:
- Als ersten Rahmen der Rahmen mit der Sequenznummer "0" gesendet.
- Die Variable NR hat den Wert "0".
- Der Empfänger wird nach Empfang des Rahmens "0" eine Quittung mit der Sequenznummer "1" senden.
- Daraufhin wird der Sender die Variable NR aud den Wert "1" setzen und den Rahmen mit der Squenznummer "1" senden.
- ... usw.
q
Alle das Protokoll betreffenden grundlegenden Eigenschaften sollten aus der Vorlesung bekannt sein, sodass Sie wissen, wie sich das Protokoll mit über das Medium erzeugten Fehlern verhält.
Verständnisfragen:
Die Fenstergröße beträgt 5. Sie senden die Pakete mit den Sequenznummern 0..4. Was passiert, wenn das Paket mit der Sequenznummer 3 verloren geht
Was wird erneut gesendet? Nach welchem Ereignis geschieht das? Hat die Fenstergröße Einfluss auf die Wahl der Sequenznummern? . . . )
Ein weiteres Beispiel: Das Acknowledgement für das erste Paket geht verloren. Was passiert?
- Korrigieren Sie die Fehler im SDL-Diagramm und testen Sie die Funktionsweise des „Go-Back-N“-Protokolls im reliable Mode und Loose-Mode. Setzen Sie hierzu die Fenstergröße auf den Wert 4. Im Loose-Mode soll jedes 3. Paket verloren gehen. Speichern Sie die MSCs und werten diese im Protokoll zum Block C aus. Für diesen Versuch werwenden Sie bitte das Skript Trial1: Test GoBackN-Protocol. Passen Sie das Skript an ihre Bedürfnisse an.
- Zeigen Sie durch Simulationen im reliable Mode, wie sich die maximale Fenstergröße auf den erzielten Durchsatz zwischen den Prozessen Source und Destination auswirkt. Verwenden Sie hierfür das Skript Trial2: Throughput vs. Windowsize. Hierzu notieren Sie sich den Wert der Variablen now und berechnen den erzielte Durchsatz. Variieren Sie die Fenstergröße vom Wert 1 bis zum Wert 32 durch Ändern der Variable Window im Sript.
- Bestimmen Sie den Durchsatz des „Go-Back-N“-Protokolls unter dem Einfluss von Bitfehleren. Verwenden Sie dabei den Bitfehlergenrerator der Bitfehler entsprechend einer Exponentialverteilung erzeugt, indem sie die Varaible MsgErrorDistr auf "1" einstellen. Es wird empfohlen für diesen Versuch das bereitgestellte Skript Trial3: Throughput vs. MeanBitErrorRate zu nutzen. Die Bedeutung der Parameter können leicht nachvollzogen werden.
Hierfür noch einige Hinweise:
- Es ist nicht notwenig die Simulation zu verfolgen während sie läuft. Setzen sie also die Trace-Level auf "0" und verzichten sie auf einen interaktiven MSC-Log. Auf diese Weise ist das Ergebnis eines Messpunktes erhältlich. Anderenfalls können die Messungen mehrere Stunden dauern!
- Sie erhalten von SDT als Ergebnis lediglich die Variable "now". Überlegen Sie sich, wie Sie aus der Variable "now" den Durchsatz berechnen können. Welche Parameter werden noch benötigt?
- Mit der Variable MsgErrMean stellen sie den Kehrwert der mittleren Fehlerwarscheinlichkeit ein. Sinnvolle Werte sind im Bereich von [1 100000] zu finden. Wird MsgErrMean" z.B. auf "2" gesetzt, dann ist im mittel jedes 2. Bit fehlerhaft. Bedenken sie, dass sie vorallem mehrere Messpunkte für mittlere bis geringe Fehlerraten (p<0.3) benötigen! Eine logarithmische Verteilung kann sinnvoll sein!
- Senden sie nicht weniger als 10000 Pakete (für den voreingestellte Breakpoint für DataConf also mindestens 20000!) pro Messpunkt! Dadurch erhalten sie zuverlässigere Ergebnisse.


 SDL System des „Send-and-Wait"-Protokolls
SDL System des „Send-and-Wait"-Protokolls